안녕하세요. 모두의 케빈입니다.
딥 러닝과 심층 신경망을 보다 깊이 알기 위해서는 회귀 분석에 대한 이해가 선행되어야 합니다.
그래서 오늘은 회귀 분석의 정의부터 딥 러닝에 실제로 활용되는 Logit, Sigmoid, Softmax의 관계까지 살펴보는 시간을 가져보고자 합니다. 긴 글이지만, 천천히 쫓아오면서 읽어주세요. :)
■ 회귀 분석의 기본적인 개념
회귀 분석은 종속 변수와 독립 변수 사이의 내재된 관계를 잘 표현하는 함수를 찾는 과정입니다. (인과관계를 증명하는 방법론이 아니라, 인과관계가 상정된 모델을 구현하는 것입니다.) 함수가 적합한지에 대한 척도로 다양한 공식이 있겠지만 가장 널리 알려진 대표적인 척도로는 MSE(Mean Square Error)가 있습니다.
MSE는 함수의 예측값과 실측 데이터 간 차이의 제곱(차이는 양수도 있고 음수도 있으니까요.)들의 평균입니다. MSE를 척도로 활용하는 선형 회귀 분석의 경우 "예측값과 실제 데이터 간 평균 오차가 가장 적은 선형 함수"를 찾도록 모델링 됩니다.
이번에는 회귀 분석을 유형에 따라 나누어보겠습니다. 우선 독립 변수의 개수에 따라 단순 회귀, 다중 회귀로 구분할 수 있습니다. 만약 데이터에 선형적인 관계가 내재되어 있다면 선형 회귀, 없으면 비선형 회귀라고 구분합니다. 또한 종속 변수가 범주형(Category)이라면 로지스틱 회귀(Logistic Regression)로 따로 구분하는 등 그 스펙트럼이 상당히 넓은 통계적 분석 방법이라고 할 수 있습니다.

(Tip) 참고로 위 수식의 왼쪽 함수는 x에 대한 비선형 회귀 함수처럼 보입니다. 하지만, 이러한 비선형 함수도 오른쪽의 함수처럼 마치 선형 관계가 있는 것처럼 충분히 표현할 수 있습니다. 이러한 방법론을 Feature Engineering이라고 합니다. 전통적인 머신 러닝 분야에서 데이터 공간(Data Space)을 탐색하며 전처리 작업으로 많이 활용되던 방법입니다. 그렇다면 도대체 비선형 함수는 어떻게 생긴 거지? 생각할 수 있습니다. 가장 단순하게는 (bx)/(1+ax^2)와 같은 형태가 있겠네요.
■ 로지스틱 회귀(Logistic Regression)
로지스틱 회귀의 기본 개념
회귀 분석에 대한 개념을 잡으셨다면, 지금부터는 집중해주세요. 로지스틱 회귀로부터 딥 러닝에 사용되는 로짓(Logit), 시그 모이드(Sigmoid), 소프트 맥스(Softmax) 함수에 대한 개념이 나옵니다.
로지스틱 회귀는 종속 변수가 범주형(Category)인 경우 사용되는 회귀 분석입니다. 환자의 생체 정보를 토대로 환자의 상태가 암이다(1), 아니다(0)를 예측하거나 기상 정보를 입력받아서 맑음(0), 흐림(1), 우천(2) 등을 예측하는 방식입니다. 어떻게 이런 방식이 가능할까요?
그건 바로 확률을 예측하는 모델을 만드는 것입니다. 실수의 입력 데이터를 토대로 종속 변수(날씨)의 Class 별 확률(맑음, 흐림, 우천 등)을 예측하는 모델을 만들고, 가장 높은 확률의 Class를 종속 변수(날씨)의 상태로 정의하면 됩니다.
선형 관계가 있는 실수의 입력값들을 토대로 확률을 예측하는 회귀 모델을 만들어 보자!
자, 그렇다면 저희에게 필요한 것은 확률을 예측하는 모델입니다. 위에서 정의한 그대로 회귀 모델을 만들면, 아래와 같은 수식이 나옵니다.

그런데 여기서 문제가 발생합니다. 예측하고자 하는 확률값 P(X)는 확률이므로 [0,1] 사이의 값만 가능합니다. 반면 우변의 선형 회귀식은 연속형 실수 공간이므로 [-∞,+∞] 사이 값을 갖습니다. 이 때문에 좌변과 우변은 등호로 같은데 범위가 다른 미스 매치가 발생합니다. 그래서 확률 값을 [-∞,+∞] 사이의 실수값으로 변환해줄 수 있는 특별한 식의 필요성이 생깁니다. 이로 인해 등장하는 것이 승산(Odds)의 개념입니다.
승산(Odds)의 등장: 확률이면서 양의 무한대 값을 갖는 개념
확률은 태생적으로 [-∞,+∞] 사이의 실수값을 가질 수 없습니다. 그래서 확률의 의미를 지니면서 동시에 넓은 범위를 커버할 수 있는 개념이 필요합니다.
승산(Odds)은 도박장에서 흔히 사용되는 개념입니다. 관심 있는 사건이 발생할 확률을 p라고 하겠습니다. 관심 있는 사건이 발생하지 않을 확률은 (1-p)입니다. Odds의 공식은 아래와 같습니다.

특정 팀이 이기는 사건에 대해 관심이 있다면, 팀이 승리하는 확률을 p로 설정할 수 있습니다. 그럼 위 수식에 의해, 승산은 지는 확률 대비 이기는 확률이 얼마나 더 큰지에 대한 비율이 됩니다. 그리고 승산이 1보다 크다면, 승리할 확률이 높다는 의미이므로 승산의 기준은 1이라고 할 수 있습니다.
이번에는 승산의 범위를 살펴보겠습니다. 확률 p는 [0,1] 사이의 값만 가질 수 있지만, 승산은 수식에 의해 p가 1에 가까울수록 분모가 0에 수렴하며 이론상 [0,+∞] 사이의 값을 갖게 됩니다.
비로소 우리는 확률의 의미를 지니면서 그 범위가 넓은 승산이라는 개념을 찾게 됩니다.
로짓(Logit)의 등장: [0,1] 사이의 값을 무한의 실수 값으로 변환
승산은 이론 상 확률의 개념이지만 [0,+∞] 사이의 값을 가질 수 있습니다. 하지만 확률로 이루어져 있기 때문에 음의 값을 취할 수 없습니다. 반면, 위에서 정의한 선형 회귀식과 동일한 의미를 지니기 위해서는 음의 무한대까지 취할 수 있어야 합니다. 이를 위해 승산에 자연로그를 취해보겠습니다.
자연로그 그래프는 [0,+∞] 사이의 입력값에 대해 [-∞,+∞] 값을 반환해줍니다. 따라서, 자연로그에 승산을 입력값을 취해주게 되면 우리는 확률의 의미를 가지면서 [-∞,+∞] 사이의 범위의 값을 변환해줄 수 있는 함수를 얻게 됩니다.

승산(Odds)에 로그 값을 취한 함수를 바로 로짓(Logit)이라고 하며, Logit은 Odds + Log의 합성어입니다. 어떤 사건이 벌어질 확률 p가 [0,1] 사이의 값일 때 이를 [-∞,+∞] 사이 실수값으로 변환하는 과정을 로짓(Logit) 변환이라고 합니다. 이러한 로짓 변환 덕분에 확률과 실수값 사이의 선형 관계성을 찾는 로지스틱 회귀가 가능해집니다. (참고로 승산은 1보다 큰지가 기준점이었다면, 로짓은 0보다 큰지가 기준점이 됩니다.)
다시 로지스틱 회귀로 돌아가서: 선형 관계가 있는 실수의 입력값들을 토대로 확률을 예측하는 회귀 모델 만들기
로짓(Logit) 변환을 통해 확률 값을 무한대 실수 값으로 변환할 수 있게 되면서, 드디어 우리는 확률을 예측하는 회귀 모델식을 가정할 수 있게 됩니다.
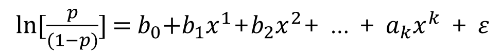
좌변과 우변이 모두 [-∞,+∞] 사이의 값을 갖게 되므로, 위 식은 동등한 관계를 집니다. 이제 여기서 확률 p에 대해 정리하기 위해 역함수를 취해보겠습니다.
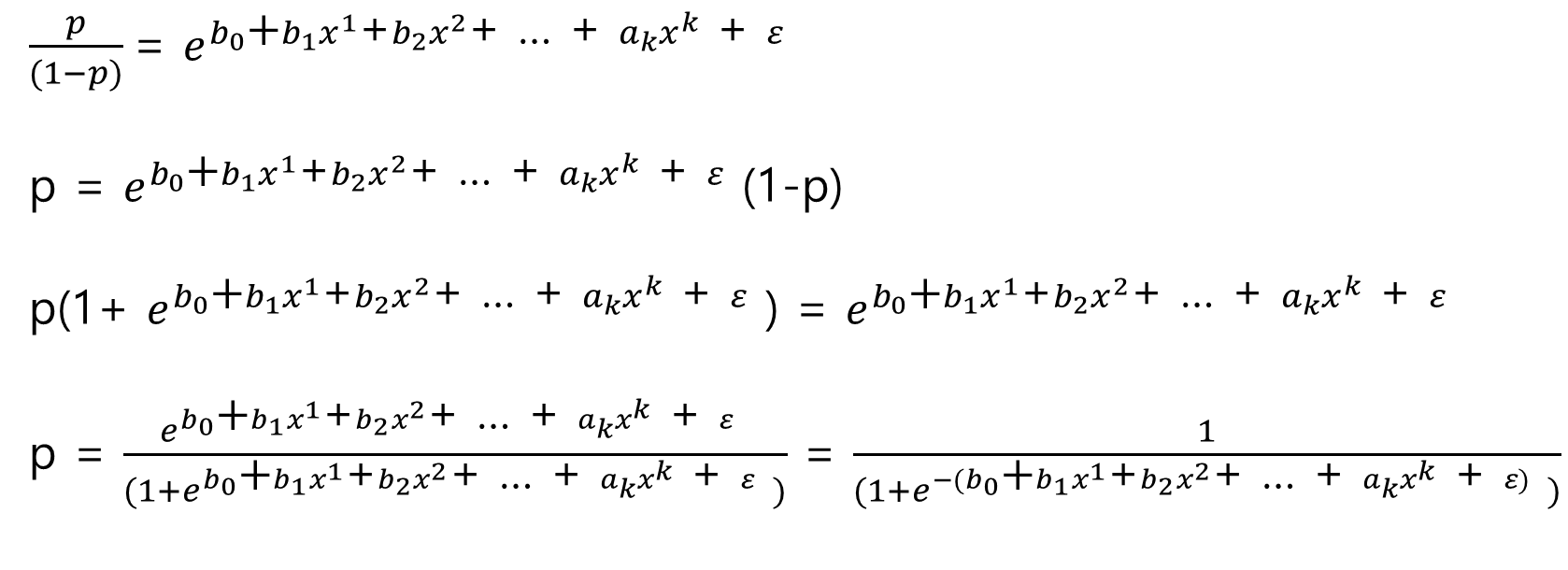
확률에 대해 정리하여 나온 최종 식을 로지스틱 함수(Logistic Function)이라고 하며, 독립 변수 x가 주어졌을 때 종속 변수가 특정 Class에 속할 확률을 의미합니다. 이 로지스틱 함수를 사용하여, 우리는 로지스틱 회귀 분석을 진행할 수 있습니다.
■ 딥 러닝에서의 의미: 로짓(Logit), 시그 모이드(Sigmoid), 소프트 맥스 함수(Softmax) 의 관계
시그 모이드(Sigmoid) 함수: 가중치 학습의 연속성을 부여하는 활성화 함수
지금까지 로지스틱 회귀와 로지스틱 함수가 유도되는 과정에 대해 배웠습니다. 여기까지 왔다면 드디어 딥 러닝에서 로짓, 시그모이드, 소프트 맥스 함수가 어떤 의미를 갖는지 이해할 준비가 모두 끝났습니다. 자, 그러면 위에서 구한 로지스틱 함수를 살짝 변형해보겠습니다.
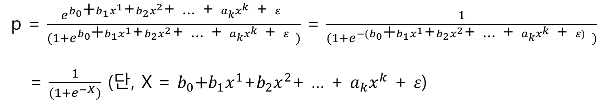
최종적으로 구한 수식이 그 유명한 시그 모이드(Sigmoid) 함수와 유사하지 않나요? 맞습니다. 로지스틱 함수는 딥 러닝에서 또 다른 말로 시그 모이드라고 사용됩니다. 인공 신경망에서 시그 모이드의 역할은 다음과 같습니다.
첫 번째, 인공 신경망의 활성화 함수로 사용됩니다. 시그 모이드 함수는 신경망의 가중치가 바뀌는 과정(학습)에 연속성을 부여합니다. 초기 신경망 모델은 계단 함수와 같은 비연속적인 활성 함수를 사용했고 학습의 효율성이 낮았습니다. 그래서 인간의 연속적인 학습 과정을 모방하기 위해 시그모이드 함수와 같은 연속적인 함수가 활성화 함수로 사용되기 시작했습니다.
두 번째, 상태가 2개인 경우에 한해서 인공 신경망의 마지막 Layer에 확률 값을 변환하는 역할로 활용될 수 있습니다. 시그 모이드 함수의 정의 자체가 Logit의 역변환이기 때문입니다.
로짓(Logit) 변환의 의미: Score
로짓(Logit)은 확률 값으로 변환되기 직전의 최종 결과 값입니다. 다른 말로는 Score라고도 합니다. 분류(Classification) 계열의 신경망 모델의 마지막 Layer에서는 소프트 맥스(Softmax) 함수가 활용되는데, 로짓 함수는 소프트 맥스 함수에 그 값을 전달해주는 역할을 합니다. (아래 소프트 맥스의 예시를 참고해주세요.)
소프트 맥스(Softmax): 멀티 Class에서 상대 비교
소프트 맥스 함수는 로지스틱 함수의 다차원 일반화 개념입니다. 종속 변수의 상태가 3개 이상인 멀티 클래스 분류 문제에서 인공 신경망의 최종 Layer로 활용됩니다.
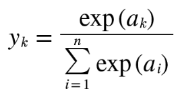
위 공식은 소프트 맥스 함수의 공식입니다. 이 공식이 어떻게 인공 신경망 내에서 동작하는지를 예시를 토대로 알아보겠습니다. 기상 정보를 토대로 날씨를 예측하는 인공 신경망이 있다고 가정하겠습니다. 날씨의 상태는 맑음, 흐림, 우천의 3가지가 있습니다.
날씨의 상태가 3가지이므로, 인공 신경망의 마지막 Layer에 있는 노드의 숫자 역시 3개입니다. 3개의 최종 노드에서 출력된 최종 값이 [2.1, 3.5, 5.6]이라고 하겠습니다. 참고로 이 값이 바로 Score이며, 로짓 변환의 결과값입니다. 이제, 인공 신경망은 이 로짓 변환의 결과 값을 활용하여 확률 값을 출력해야 합니다. 아래는 Logit 값이 어떻게 Softmax 함수를 통과하여 확률 값으로 변하는지를 나타내는 과정입니다.
1. [2.1, 3.5, 5.6]에 지수 함수를 취하면, [e(2.1), e(3.5), e(5.6)] = [8.2, 33.1, 270.4]
2. Summation 하여 분모로 나누어주면, [8.2/(8.2+33.1+270.4), 33.1/(8.2+33.1+270.4), 270.4/(8.2+33.1+270.4)]
3. 최종 결과: Logit [2.1, 3.5, 5.6] → Softmax [0.03, 0.11, 0.86]
4. [맑음, 흐림, 우천] = [0.03, 0.11, 0.86] 이므로 신경망은 날씨 상태를 "우천"으로 예측
참고로 Logit 값을 그대로 사용하지 않고, 지수함수를 취하는 이유는 값들 간의 차이를 더욱 두드러지게 하여 신경망 학습이 잘 되도록 하기 위함입니다.
오늘은 회귀에 대한 기초 개념부터, 소프트 맥스 함수까지 살펴보았습니다.
궁금한 점은 댓글 남겨주시면 상세히 설명드리겠습니다. 긴 글 읽어주셔서 감사합니다.
'AI - Deep Learning' 카테고리의 다른 글
| 딥 러닝이란 무엇인가? 한 글로 끝내기 (0) | 2022.11.02 |
|---|---|
| 활성화 함수: 정의와 종류, 비선형 함수를 사용해야 하는 이유 (0) | 2022.11.01 |
| 인공지능(AI) 배경지식: 용어의 유래부터 현재의 딥러닝(DNN)까지 (2) | 2022.10.14 |
| 인공 신경망 학습 원리와 기울기 소실 문제 정의 및 해결법 한 글로 정리 (1) | 2022.10.13 |
| 최초의 신경망 모델 퍼셉트론: 정의, 동작 원리 그리고 한계점 (2) | 2022.10.11 |




댓글