목차
원본 논문: https://arxiv.org/pdf/1501.00092.pdf
#1,2 Introduction and Related Work
> SRCNN의 장점
> SRCNN의 업적
> SRCNN Layer 별 역할
> 기존 방식과 SRCNN의 비교 분석
> [1] 데이터셋의 크기에 따른 모델의 성능 차이 비교
> [2] 모델의 크기에 따른 성능 차이 비교
> [3] 필터 크기에 따른 모델의 성능 차이 비교
> [4] 모델의 깊이에 따른 성능 차이 비교
이 글은 논문을 순서대로 해석하며 작성한 글입니다. 원본 논문과 같이 화면 분할하여 함께 보시는 것을 권장드립니다. 또한 글이 길기 때문에 "Conclusion" 부분을 먼저 읽고 본문을 읽으시면 이해하시는데 더 도움이 될 것 같습니다. 마지막으로 독학으로 공부하고 있기 때문에 일부 잘못 해석한 부분이 있을 수 있습니다. 혹시 내용에 오타가 있다면 댓글 남겨주시면 수정하도록 하겠습니다. :)
#1,2 Introduction and Related Work
저해상도 이미지에서 고해상도 이미지를 복원(recovering)하는 분야인 Single Image Super-Resolution(SR)은 컴퓨터 비전에서 전통적인 문제입니다. 그런데 이러한 문제는 본질적으로 "ill-posed" 문제, 즉 정답이 없는 문제입니다.
잠깐 아래 사진을 보실까요? 보는 사람에 따라서 어떤 사람의 눈에는 HR2가 고해상도로 보이기도 하고, 다른 사람의 눈에는 HR3가 고해상도로 보일 수 있습니다. 하나의 저해상도 이미지에서 정답 고해상도 이미지가 여러 개 나올 수 있다는 말이죠.
이처럼 입력과 출력값이 1:1로 매칭되는 것이 아니라 여러 정답이 있을 수 있는 문제를 "ill-posed" 문제로 정의합니다. 초해상도(Super-Resolution) 분야는 이러한 문제 때문에 해결하기 어려운 분야에 속합니다.

이러한 ill-posed 문제를 해결하기 위한 대표적인 방법으로 외부 경험 기반(External example-based) 방식 중, 희소 코딩 기법(Sparse-Coding-based)이 있습니다. 이 기법은 저해상도, 고해상도 이미지를 쌍으로 준비하여 정답 공간을 제한하는 방식입니다. 마치 답정너처럼 "여러 개의 정답이 있지만 내가 원하는 정답은 이거야!"라고 모델에게 미리 제시하는 셈입니다.
희소 코딩 기법(Sparse-coding-based)은 크게 두 가지 스텝으로 이루어져 있는데요. 먼저 이미지로부터 패치를 추출하고 이를 저해상도 딕셔너리에 맵핑합니다. 그리고 저해상도 딕셔너리로부터 고해상도 이미지를 표현할 수 있는 고해상도 딕셔너리의 관계를 해석하고 이를 고해상도 이미지 복원에 활용하는 방식입니다. 지금은 이해하기 어려우실 텐데요. 자세한 건 아래에서 SRCNN의 구조를 설명드리면서 자세하게 비교 설명드리겠습니다.
이 논문에서는 기존의 희소 코딩 기법이 데이터를 처리하는 모든 Pipeline에서 최적화하는 것이 아니라 특정 국부적인 단위에서만 최적화를 시킨다고 지적합니다.
예시를 들어보겠습니다. 데이터를 입력받아서 특징을 추출하고 결과물을 출력하기까지의 모든 과정이 있을 텐데, 희소 코딩 기법은 특징을 추출하는 부분만 최적화를 시키는 겁니다. 나머지 부분은 사용자의 하드 코딩으로 이루어지고요. 이렇게 되면 데이터를 입력하는 과정과 결과물을 출력하는 과정에서 최적화시킬 수 있는 기회를 놓치게 되는 겁니다.
그래서 저자들은 CNN(Convolution Neural Network)를 활용한 SRCNN 방법을 제안하는데요. SRCNN은 기존의 방식들에서 수행하는 모든 과정(패치를 추출해서 특징을 파악하고 결과물까지 출력하는)이 Hidden Layer로 대체될 수 있다고 제안합니다. 그리고 딥러닝 특성상 모든 Layer가 유기적으로 연결되어 있기 때문에 모든 Pipeline이 최적화된다고 주장합니다.
자 그럼, 저자들이 말한 SRCNN의 장점과 어떤 점을 AI 분야에 기여했는지 살펴볼까요.
SRCNN의 장점
1. 구조가 굉장히 간결하고 직관적이지만 기존의 방법들 대비 뛰어는 정확도를 자랑한다.
2. CPU에서 동작할 수 있을 정도로 실용적이다.
3. 더 많은 데이터를 사용할수록, 모델이 더 깊어질수록 성능 향상 가능성이 있으며 컬러 이미지 채널에서도 동작한다.
SRCNN의 업적
1. 초해상도(Super-Resolution) 분야에 CNN을 적용했고, 이를 통해 입력부터 출력까지 end-to-end 최적화가 가능해졌다.
2. 딥러닝 기반의 방식과 기존 'Sparse-coding-based' 방식의 비교 분석을 통해 추후 새로운 모델을 설계할 때 참고할 수 있는 가이드라인을 제시했다.
3. 딥러닝이 초해상도 분야에서도 뛰어난 성과를 낼 수 있다는 것을 증명했다.
※ "#2 Related work"에 대해서는 Introduction의 내용과 중복되므로 생략하도록 하겠습니다.
#3 Convolution Neural Network For Super-Resolution
논문의 꽃인 모델의 아키텍처에 대해 살표 보겠습니다. SRCNN에게 주어진 Task는 고해상도 이미지 X로부터 저해상도 이미지 Y를 추출하고, F(Y)가 X와 유사해지도록 하는 함수 F를 찾는 것입니다.
저해상도 이미지 'Y'는 고해상도 이미지 'X'를 랜덤으로 자르고(Random Crop) 잘라진 이미지를 Bicubic interpolation으로 업스케일링하여 얻습니다. 이해하기 쉽게 설명드리면, 이미지의 특정 부분을 확대해 보신 경험이 있으실 겁니다. 그러면 확대한 부분에는 픽셀이 깨지면서 경계면이 흐릿해 보이는데요. 업스케일링했다는 말은 이처럼 특정 부분을 크게 확대했다는 의미입니다.
이미지를 확대하게 되면, 픽셀과 픽셀 사이의 간격이 멀어지게 되고 이를 어떤 규칙에 의해 채워줘야 하는데요. Bicubic 보간법은 그렇게 넓어진 픽셀과 픽셀 사이를 채우는 방법 중 하나입니다. (자세한 내용은 본문 아래에 나무위키 링크를 넣어 두었으니 궁금하신 분들은 참고해 주세요.)

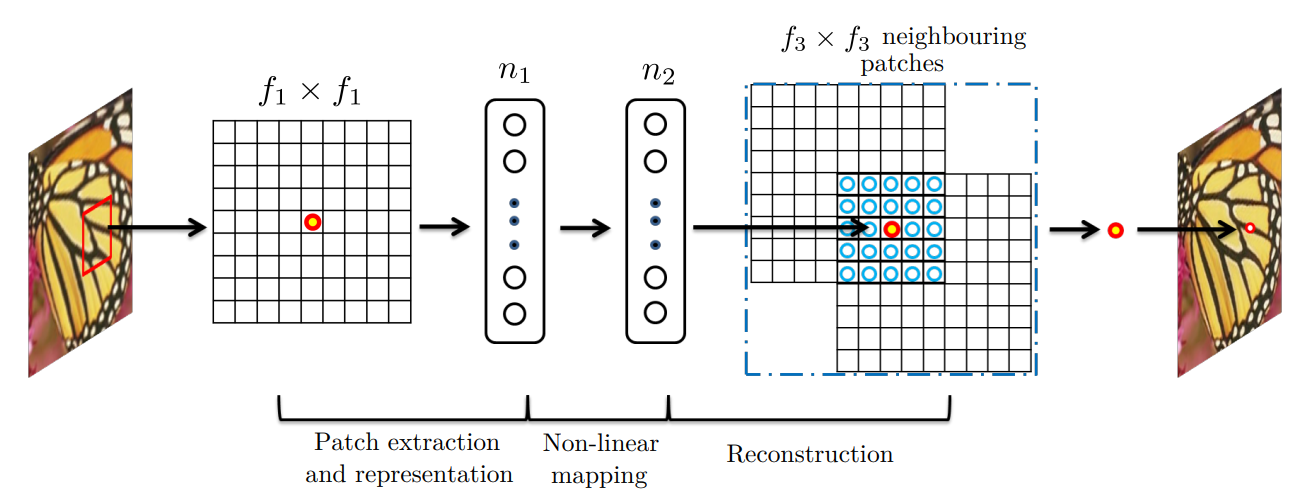
위의 이미지는 SRCNN의 구조인데요. SRCNN은 3개의 Convolution Layer로 이루어져 있습니다. 구조는 단순하지만 각각의 Layer에는 과거의 방법에서 수행한 고유의 역할들이 부여됩니다.
SRCNN Layer 별 역할
첫 번째 Layer는 저해상도 이미지를 입력받아서 "Patch extraction and representation" 역할을 수행합니다. 논문에서는 이 과정이 저해상도 이미지로부터 여러 패치를 추출하고 이를 feature map의 집합으로 바꾼다고 되어있는데요. 쉽게 Conv Layer가 저해상도 이미지를 Scan 한다고 생각하시면 됩니다. CNN의 특성상 이렇게 추출된 feature map은 일종의 '표현(Representation)'이 되는데요. 논문에서는 이 feature map들이 저해상도 이미지 패치의 표현이라고 합니다.
두 번째 Layer는 저해상도 이미지 패치의 표현, Feature Map들을 비선형 맵핑(Non-linear Mapping)하여 고해상도 패치의 표현으로 변환하는 역할을 합니다. (물론 이 역시 쉽게 해석하면 필터 크기가 1인, 1x1 Conv 작업을 수행하는 것입니다.)
그리고 마지막 세 번째 Layer는 고해상도 패치의 표현들, featrue map으로부터 최종 고해상도 이미지를 복원(Reconstruction)하는 역할을 합니다. 그리고 이렇게 복원된 이미지, F(Y)가 원본 고해상도 이미지(Ground Truth) X와 유사하다면 학습은 성공적인 것으로 판단합니다.
여기까지 읽으셨다면 이러한 궁금증이 드실 수 있습니다. "왜 Pooling Layer를 사용하지 않았을까?"
그 이유는 SRCNN 자체가 위에서 언급했던 기존의 SOTA 방법인 'sparse-coding-based'를 딥러닝 버전으로 바꾼 알고리즘이기 때문입니다. 과거 방법의 아키텍처를 그대로 흉내 내어 딥러닝 버전으로 바꾸고 성능을 비교 분석한 것이 핵심인데, 과거 방식에는 Pooling이 없으므로 SRCNN에서도 Pooling Layer를 채택하지 않았습니다.
#3-2 기존 방식과 SRCNN의 비교 분석(Relationship to Sparse-Coding-Based Methods)
위의 그림은 과거 SR 분야에서 인기 있었던 희소 코딩 기법(Sparse Coding Based)의 아키텍처입니다. SRCNN 하고 상당히 유사합니다.
SRCNN이 희소 코딩 기법의 구조를 참고했다고 했으니, 본격적으로 두 기법을 1:1로 비교해 보도록 하겠습니다.
먼저 'Patch extraction and representation' 부문입니다. 희소 코딩도 처음에는 저해상도 이미지로부터 패치를 추출하면서 시작합니다. 그리고 이 패치를 저해상도-딕셔너리에 투영합니다. 이렇게 투영된 딕셔너리가 n1입니다. 반면 SRCNN에서는 이미지 패치를 추출하서 저해상도 이미지의 특징을 뽑아내는 과정을 첫 번째 Convolution Layer가 모두 담당하여 처리합니다.
두 번째로 'Non-linear Mapping'입니다. 희소 코딩 기법은 'Solver'라는 알고리즘이 있는데, 이 알고리즘은 저해상도 딕셔너리로부터 고해상도 딕셔너리를 연산하는 역할을 수행합니다. SRCNN에서는 이 과정을 두 번째 Convolution Layer가 담당하는데요. 희소 코딩 기법과 유사한 기능을 수행할 수 있도록 필터 사이즈를 1로 설정합니다. (필터 사이즈가 1이면 입력과 출력의 이미지가 1:1 맵핑됩니다.) 물론 희소 코딩 기법은 딥러닝이 아니기 때문에 'Fully feed-forward' 방식이 아니라 단순하게 반복적인 방식으로 n1과 n2 사이의 관계를 구합니다. (당연히 SRCNN의 성능이 좋을 수밖에 없겠네요.)
마지막으로 'Reconstruction' 과정입니다. 희소 코딩의 경우에는 예측된 고해상도 패치 정보들의 평균으로 고해상도 이미지를 복원합니다. SRCNN도 이 과정은 크게 다르지 않습니다. Conv Layer를 활용하여 feature map들을 평균내고 처음 입력받은 저해상도 이미지의 채널과 동일하도록 맞춰서 고해상도 이미지를 복원합니다. (평균을 구하는 희소 코딩의 마지막 과정과 최대한 유사하도록 SRCNN의 마지막 Conv Layer에서는 비선형 함수를 통과시키지 않고 linear 함수를 통과시킵니다.)
두 기법은 유사하지만 성능은 SRCNN이 뛰어납니다. 성능이 차이 나는 이유는 크게 두 가지입니다. 먼저 최적화 정도입니다. 분명 데이터를 입력받는 순간부터 최적화의 기회가 있지만 희소 코딩은 딕셔너리를 구하는 과정만 국부적으로 최적화시킵니다. 반면 SRCNN은 데이터를 입력받아서 저해상도 딕셔너리를 구하고, 이를 고해상도 표현으로 바꾸고 복원하는 모든 과정이 Hyper-Parameter, 튜닝하는 파라미터(Conv Layer)로 이루어져 있기 때문에 모든 과정이 유기적으로 최적화됩니다. 뿐만 아니라 저해상도 이미지만 넣어주면 고해상도 이미지가 나오는 'end-to-end' 학습이 가능하죠.
그리고 고해상도 이미지를 복원할 때 주위의 픽셀값을 얼마나 활용하는지에 대한 차이입니다. 희소 코딩은 고해상도 픽셀 한 개를 복원할 때 81개 정도만 참고하지만 SRCNN은 169개의 픽셀을 활용한다고 하네요.
#3-3 Training
SRCNN은 저해상도 이미지 Y가 있을 때, F(Y)가 고해상도 이미지 X와 비슷해지도록 하는 F를 최적화하는 것이 목표입니다. F는 3개의 Conv Layer의 weights와 bias vectors의 집합으로 표현할 수 있습니다. 손실 함수는 MSE를 사용하며, 저해상도와 고해상도 이미지의 픽셀값의 차이를 계산합니다.
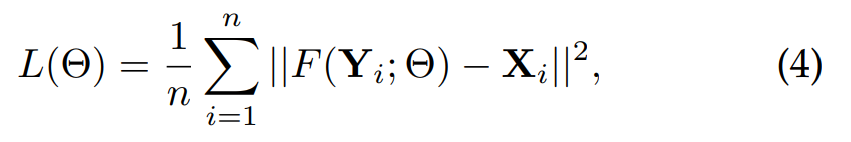
평가 metrics는 PSNR을 사용합니다. PSNR는 최대 신호 대비 잡음의 비율인데 주로 이미지 복원 분야에서 평가 지표로 많이 활용됩니다. 참고로 SRCNN의 또 다른 장점 중 하나는 손실 함수나 평가 metric에 대한 제약이 없다는 점입니다. 딥러닝이기 때문에 더 좋은 지표가 있다면 언제든지 바꿀 수 있는데, 이런 유연성이 기존 방식들 대비 또 다른 장점이겠네요.
각 Conv Layer의 weights는 평균이 0이고 표준 편차가 0.001인 가우시안 분포로 랜덤 하게 초기화(bias는 0)됩니다. 그리고 처음 두 개의 Conv Layer의 학습률은 0.0001, 마지막 Conv Layer는 0.00001로 다르게 설정합니다. 이는 저자들이 시행착오를 겪으며 실험적으로 얻은 값이라고 설명합니다.
입력 이미지는 저해상도 이미지이며 이는 고해상도 이미지로부터 전처리를 통해 만듭니다. 먼저 Ground Truth, 줄여서 GT라고 부르는 고해상도 이미지 X를 랜덤 하게 Crop 합니다. 잘라낸 이미지를 가우시안 커널(Gaussian Kernel)로 blur처리하고 Bicubic interpolation을 활용하여 Upscaling Factor만큼 이미지를 업스케일링합니다.
출력 이미지는 입력 이미지로부터 추출한 feature map들을 처리하고 평균을 내는 과정에서 입력이미지보다 크기가 작아집니다.
#4 Experiments
저자들은 SRCNN을 활용하여 여러 실험을 합니다. 참고로 SRCNN은 Color 채널에도 적용 가능하지만, 과거의 방법들과 성능을 비교하기 위해서 우선은 Y채널(1 채널)에 대해서만 초해상도 작업을 진행합니다. 각각의 실험들과 시사점에 대해 간략하게 정리해 보겠습니다.
[1] 데이터셋의 크기에 따른 모델의 성능 차이 비교
두 개의 데이터셋이 있습니다. 하나는 91개의 고해상도 이미지를 24,800개의 저해상도 이미지로 자른 데이터셋입니다. 다른 하나는 약 40만 개가 넘는 이미지 데이터셋입니다. (물론 이것도 잘라서 5백만 개? 이미지가 됩니다.)
SRCNN의 다른 파라미터는 고정하고 두 개의 데이터셋으로 모델을 따로 학습시킵니다. 성능의 평가는 Set5라는 데이터셋을 활용했습니다. 결과는 당연히 크기가 큰 데이터셋으로 학습한 SRCNN의 성능이 더 좋게 나오는데요. 그러나 성능의 차이가 생각보다 크지 않습니다. 논문에서는 그 이유를 "SRCNN 모델이 간단해서 91개 이미지 데이터셋만으로도 이미지의 변화를 충분히 학습해서 그런 것"이라고 설명합니다. 모델의 Capacity가 워낙 작으니, 데이터셋의 크기가 작아도 오버피팅 되지 않는 셈입니다.
그렇지만 거꾸로 말하면 모델을 유의미하게 더 깊이 쌓을 수 있다면 더 큰 데이터셋을 학습에 활용하여 성능 향상을 시킬 수 있다는 의미도 되겠네요.
[2] 모델의 크기에 따른 성능 차이 비교
두 번째로는 Layer의 뉴런을 늘리는 등 모델의 크기를 키워서 실험을 하는데요. 이 역시 성능 향상이 이루어지지만 속도와 trade-off 관계가 있으니 목적에 맞는 적절한 모델의 크기를 선택하라고 제시합니다. 이 논문이 발표할 당시에는 가장 기본적인 구조의 SRCNN이 SOTA를 달성했으니 굳이 더 큰 모델을 선택할 필요가 없었던 셈입니다.
[3] 필터 크기에 따른 모델의 성능 차이 비교
세 번째 실험에서는 각 Convolution Layer의 필터 크기를 바꿔보는데요. 필터의 크기가 어느 정도 합리적인 수준으로 키우면 결과가 더 좋아지는 것을 확인할 수 있습니다. 그 이유는 필터의 크기가 크면 이미지 복원 과정에서 인접 픽셀의 구조적인 정보를 더 활용할 수 있기 때문입니다. (물론 필터의 크기가 너무 크면 관련 없는 픽셀의 정보까지 들어오니 성능이 떨어질 것으로 보입니다.)
[4] 모델의 깊이에 따른 성능 차이 비교
네 번째로는 모델을 더 깊게 쌓아서 성능의 차이가 있는지를 비교했습니다. 일반적으로 CNN은 모델이 깊을수록 효과적으로 알려져 있으니까요. 하지만 SRCNN은 모델을 깊게 쌓아도 성능이 크게 좋아지지 않았는데, 저자들은 SR 분야에서는 'The Deeper the better'이라는 말이 성립되지 않을 수 있겠다,라는 의견을 제시합니다.
[5] Color 채널에 대한 실험
나머지 실험들에 대해서는 생략하고, 마지막으로 Color 채널에 대한 실험에 대해 설명드리겠습니다. 기존의 방식에서는 Gray-Scale(1 채널) 이미지만 초해상도 작업을 진행했다고 말씀드렸습니다.
Color 채널인 경우, RGB 코딩을 YCrCb 코딩으로 바꾸고 Y 채널에 대해서만 초해상도를 적용하고 남은 CrCb 채널은 단순하게 Bicubic 기법으로 업스케일링하여 Y채널과 합쳐서 결과물을 출력했습니다.
기본적으로 Cb, Cr 채널이 Y채널에 비해 더 흐릿한 경향이 있어서 downsample 과정에서 영향이 적은데요. 이는 Y채널은 저해상도로 만드는 과정에서 차이가 크게 확 바뀌지만 Cr과 Cb는 애초에 이미지가 흐릿하기 때문에 덜 바뀐다는 의미입니다. 모델의 입장에서는 차이가 큰 Y채널의 이미지에 대해서는 많은 필터가 반응하지만 Cr, Cb 채널에서는 저해상도와 고해상도 간 차이가 작기 때문에 필터가 덜 반응하게 됩니다. 이렇게 되면 모델의 학습이 Y채널에 편향(Biased)되게 됩니다. 따라서 CrCb 채널이 마치 학습을 방해하는 것처럼 작용하기 때문에 과거에는 Y 채널에 대해서만 초해상도 작업을 진행했던 것입니다.
그렇지만 SRCNN 모델은 이러한 한계를 극복합니다. 뿐만 아니라 CNN 기반이기 때문에 RGB 이미지를 굳이 YCrCb 채널로 변경할 필요 없이 RGB 이미지를 처리할 수 있습니다. 실제로 SRCNN의 경우 RGB 채널 이미지로 학습된 SRCNN의 성능이 더 좋다고 하네요.
#5 Conclusion
드디어 논문의 결론 부분입니다. SRCNN이 초해상도 분야에서 어떤 기여를 했는지를 마지막으로 강조하고 논문을 마무리합니다.
1. SR 분야에 CNN을 적용하여 기존의 SOTA인 희소 코딩 기법을 딥러닝 버전으로 재구성했다.
2. End-to-End 학습을 구현했으며 최소한의 전/후처리만으로 학습의 전반적인 Pipeline을 최적화했다.
3. 기본 모델만으로 SOTA를 달성했으며, 학습 전략(모델의 구조, 깊이 등)에 따라 성능 향상의 가능성이 있음을 증명했다.
다음 시간에는 SRCNN을 실제 파이썬 코드로 구현해 보도록 하겠습니다. 긴 글 읽어주셔서 감사합니다.
https://namu.wiki/w/%EC%9D%B4%EB%AF%B8%EC%A7%80%20%EB%B3%B4%EA%B0%84
이미지 보간 - 나무위키
이미지 보간은 주변 픽셀의 값을 기반으로 수학적인 보간법을 사용하여 새 픽셀의 값을 추정하는 방식으로 작동한다. 이 수학적 보간법을 얼마나 복잡하고 정밀한 것을 쓰느냐에 따라 그 결과
namu.wiki
'AI - Deep Learning > Super_Resolution' 카테고리의 다른 글
| [논문 구현] SRGAN(by Pytorch)을 활용한 Super Resolution Code (0) | 2023.06.27 |
|---|---|
| [논문 리뷰] SRGAN 논문 완벽 정리: Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (0) | 2023.06.21 |
| [논문 구현] SRCNN(by Pytorch)을 활용한 Super Resolution (6) | 2023.06.14 |
| [논문 구현] SRCNN(by Keras)을 활용한 Super Resolution (4) | 2023.06.13 |




댓글