논문 제목: Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network(2017)
논문 링크: https://arxiv.org/pdf/1609.04802.pdf
목차
> 기존 방법들에 대한 단점이 보이기 시작하다.
> MSE는 사람의 지각적 감각을 재현하기 어렵다.
> 사람의 감각을 공감하고 재현할 수 있는 방법을 제안하다.
> SRGAN의 목적함수
> 생성자(Generator)와 판별자(Discriminator)의 구조
> SRGAN을 학습시키는 방법
> 12개의 다른 모델과의 성능 비교
#4,5 Discuission and future work / Conclusion
> SRGAN의 성과
#1 Abstarct & Introduction
SR 분야에서 기존 방법들이 가진 단점들이 보이기 시작하다.
논문이 발표된 2017년을 기준으로 SR(Super-Resolution, 초해상도) 분야에서는 CNN이 다양하게 활용되고 있었습니다. 하지만 공통적으로 업스케일 정도(Upscale Factor)가 큰 경우에는 미세한 질감(finer texture details)을 복구하는데 어려움이 있다는 문제점을 갖고 있었습니다. 그 이유는 기존 모델들이 사용하는 목적 함수(Objective function)에 있습니다.
초기 SRCNN을 비롯한 대부분의 모델이 목적 함수로 MSE를 채택했습니다. MSE는 Pixelwise 연산으로 PSNR 수치는 높게 얻을 수 있지만, 사람이 고화질이라고 느끼는 지각적(Perceptual) 감각을 전혀 표현할 수 없습니다. 또한 고주파수 디테일(high-frequency details)의 표현이 상당히 떨어집니다.
아래 이미지에서 PSNR과 MSE 기반 모델의 단점이 보입니다. PSNR 수치는 SRResNet이 가장 높지만 SRGAN의 이미지가 사람의 눈에는 보다 더 고화질 이미지처럼 보입니다. 또한 목 부분을 보면 원본 이미지의 미세한 질감을 SRGAN 이외의 모델은 전부 부드럽게 뭉개서 표현하고 있는 것처럼 보입니다. MSE 자체가 Pixelwise "평균"이기 때문에 발생하는 현상입니다.

MSE 기반 학습의 문제점: 사람의 지각적 감각을 재현하지 못하다.
MSE Loss의 단점을 조금 더 자세하게 살펴보겠습니다. 아래의 이미지를 봐주세요. 오른쪽의 이미지는 왼쪽의 고해상도 이미지를 오른쪽으로 한 칸(1 Pixel)씩 평행 이동한 이미지입니다. 만약 이 글을 읽고 있는 독자님들을 비롯하여 여러 사람들이 두 이미지의 해상도를 평가한다고 해볼까요. 아마 두 이미지의 해상도가 비슷한 수준이라고 평가할 가능성이 높습니다. 왜냐면 단순히 평행 이동을 했을 뿐이니까요.
그러나 MSE를 기반으로 학습된 모델의 입장에서는 그렇지 않습니다. MSE는 같은 위치의 픽셀끼리의 값의 차이(Pixel-wise)를 구합니다. 따라서 모델은 평행 이동을 한 두 이미지의 해상도가 전혀 다르다고 판단합니다. 같은 위치의 픽셀에 다른 정보가 들어가 있으니까요. 그래서 MSE를 활용하여 SR 모델을 학습하면 스무딩(Smoothing) 현상이 발생합니다. 세밀하고 섬세한 픽셀의 정보들을 옆으로 넓게 퍼트리고 뭉개서 Pixel-wise 기반의 MSE를 최소화하기 때문입니다.
사람의 감각을 공감하고 재현할 수 있는 방법을 제안하다.
따라서 저자들은 이러한 문제들을 해결하기 위해 새로운 아키텍처와 손실 함수(Loss function), 그리고 테스트 기법을 제안합니다. 우선 큰 틀에서 정리해 드리고, 자세한 내용은 아래에서 다시 설명드리겠습니다.
[1] 새로운 아키텍처: GAN(Generative adversial network)을 활용한 SR 모델, SRGAN
GAN을 활용하여 "4x Upscaling"이 가능한 최초의 Framework를 구현했습니다. GAN은 원본 이미지와 유사한, '그럴듯한' 이미지를 생성하는데 특화가 되어 있는 모델입니다. 진짜와 가짜를 구분하는 판별자를 속이기 위해 생성자는 원본 이미지의 데이터 공간(manifold) 쪽으로 점점 접근하여 특징을 탐색합니다. 그래서 SR 분야에 GAN을 활용하면 원본 이미지의 미세한 질감(detail texture)을 잘 보존한 고해상도 이미지를 만들 수 있다는 장점이 있습니다.
구조적으로는 배치 정규화(Batch Normalization), 잔차 블록(residual blocks), 스킵 커넥션(Skip Connection)을 활용합니다. 심층 신경망은 모델의 깊이가 깊어질수록 Loss가 사라지는 단점이 있는데요. 스킵 커넥션을 활용하면 정보를 모델의 깊은 곳까지 전달할 수 있다는 장점이 있습니다.
[2] 새로운 손실 함수: 지각적 손실 함수(Perceptual Loss function)
지각적 손실 함수는 사람이 느끼는 고해상도 이미지와 가까워지기 위해 고안된 손실 함수입니다. "Adversarial Loss"와 "Content Loss"의 가중치 합(Weighted Sum)으로 구성됩니다.
Adversarial loss는 GAN에서 생성자(Generator)의 Loss입니다. 생성자는 진짜 같은 가짜 이미지를 만들어서 판별자를 속이도록 학습됩니다. 따라서 생성자 Loss를 Total Loss에 포함시키면 생성하는 SR 이미지가 실제 이미지의 데이터 공간 근처에서 생성되도록 가속(Push)할 수 있습니다.
Content loss는 MSE의 Pixel 단위의 유사성을 지각적 유사성(Perceptual similarity)으로 대체하기 위해 제안된 손실 함수입니다. 이 논문에서는 분류작업(Classification)을 위해 사전 학습된(Pre-trained) VGG19 모델의 가중치를 활용했습니다. 사전 훈련된 모델을 사용한 이유는 기존 데이터의 표현(Representation)을 잘 담고 있기 때문입니다.
생성자가 만든 가짜 고해상도 이미지와 진짜 고해상도 원본 이미지를 사전 훈련된 모델에 통과시키면 최종 결과물로 Feature Map을 얻게 됩니다. 이 두 Feature Map 간의 차이를 구하는 것이 바로 Content Loss입니다. Feature Map 간 차이는 곧 표현의 차이를 구하는 것이기 때문에 간극(Gap)을 줄이기 위해 생성자는 진짜 데이터의 표현을 잘 따라 하도록 학습이 진행됩니다.
따라서 Adversarial Loss와 Content Loss의 가중치 합으로 구성된 지각적 손실 함수는 실제 고해상도 이미지 데이터 공간 근처에서 원본 표현을 잘 따라 하는 SR이미지를 만들 수 있게 도와주는 함수가 되겠네요.
[3] 새로운 테스트 기법: MOS(Mean opinion score)
기존 SR 분야에서 사용되었던 PSNR이나 SSIM은 MSE 기반의 계산 방식이기 때문에 이미지 성능 평가에 적합하지 않습니다. 그래서 저자들은 MOS 테스트를 활용하자고 제안합니다. MOS는 26명의 사람에게 1점(bad)부터 5점(excellent)까지 점수를 매기도록 한 것입니다. (물론, 저자들이 처음 제안한 것은 아니고 다른 분야에서 활용되고 있는 지표를 SR 분야에 새롭게 도입한 것입니다.)
#2 Method
학습 데이터는 어떻게 구성하나요?
학습 데이터 구성하기
이제 SRGAN을 학습시키는 방법에 대해 알아보도록 하겠습니다. 우선 학습 데이터를 어떻게 만드는지 살펴볼까요. SISR 분야의 목적은 저해상도 이미지로부터 고해상도 이미지를 추정하는 것입니다. 따라서 학습에는 (저해상도, 고해상도) Paired 이미지가 필요합니다.
저해상도 이미지는 고해상도 이미지에 가우시안 필터(Gaussian filter)를 적용한 다음 가로, 세로를 r배(Downsampling factor) 줄임으로써 얻을 수 있습니다. 원본 고해상도 이미지의 크기가 rW x rH x C라고 한다면, 생성된 저해상도 이미지의 크기는 W × H × C 가 됩니다.
SRGAN의 목적 함수는 어떻게 되나요?
SRGAN 목적 함수
먼저 판별자의 목적 함수를 살펴볼까요. 일반적으로 GAN에서는 진짜는 1로, 가짜는 0으로 정의합니다. 이상적인 판별자는 진짜 이미지를 진짜, 1로 판단해야 합니다. 따라서 진짜 고해상도 이미지 I(HR)이 판별자에 입력되면 log(1) = 0이 돼야 합니다. 반대로 가짜 이미지는 가짜, 0으로 판단해야 합니다. log(1-0) = 0이죠. 따라서 판별자는 최댓값이 0인 목적함수를 0에 가까워지도록 최대화해야 합니다.
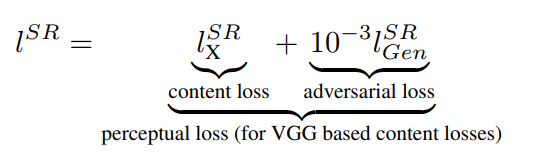
다음으로 생성자의 목적 함수를 살펴보겠습니다. 생성자의 목표는 Content Loss와 Adversarial Loss의 가중치 합으로 구성된 지각적 손실 함수(Perceptual Loss)를 최소화하는 것입니다.
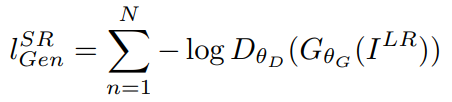
먼저 생성자의 Adversarial Loss는 일반적인 GAN에서 생성자의 Loss 함수 공식과 동일합니다. 형태를 보면 판별자의 목적 함수에서 뒷부분만 차용한 형태인데요. 생성자는 진짜 같은 가짜 이미지를 만드는 것이 목표이므로 판별자의 목적 함수에서 앞부분은 필요가 없습니다. 여기서 log(1-D)가 아니라 -log(D)인 이유는 동일한 의미이지만 -log(D)로 표현하는 게 학습 초기 모델의 학습 속도가 빠르기 때문입니다.
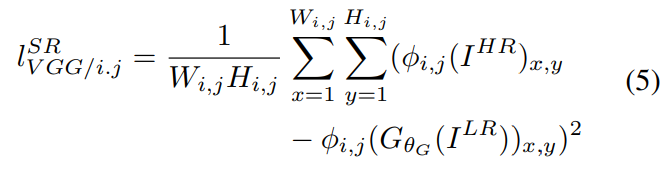
다음으로 Content Loss는 SRGAN에서 생성자의 목적 함수에 추가된 특별한 공식입니다. 수식이 정말 어려워 보이는데, 쉽게 설명드리겠습니다.
생성자가 생성한 가짜 이미지와 원본 진짜 이미지를 사전 학습된 VGG19 모델에 통과시킵니다. 물론 마지막 Layer까지는 아니고, 바로 직전(활성함수 ReLU Layer를 통과하고 Max-Pooling Layer을 통과하기 전) 까지요. 그러면 각각 Feature Map들을 얻을 수 있습니다.
Content Loss는 이들 Feature Map 끼리의 MSE입니다. 공식을 잘 보시면, Feature Map끼리 element-wise 연산 후 제곱하여 전체 원소의 개수로 평균을 구하는 형태인데 이는 MSE의 공식과 정확히 동일합니다.
기존 이미지는 가짜 이미지와 실제 고해상도 이미지를 직접 비교하여 MSE를 구했다면, Content Loss는 간접적으로 Feature Map 끼리의 MSE를 구하는 셈입니다. (이렇게 하는 이유는 Introduction 쪽에서 말씀드렸습니다.)
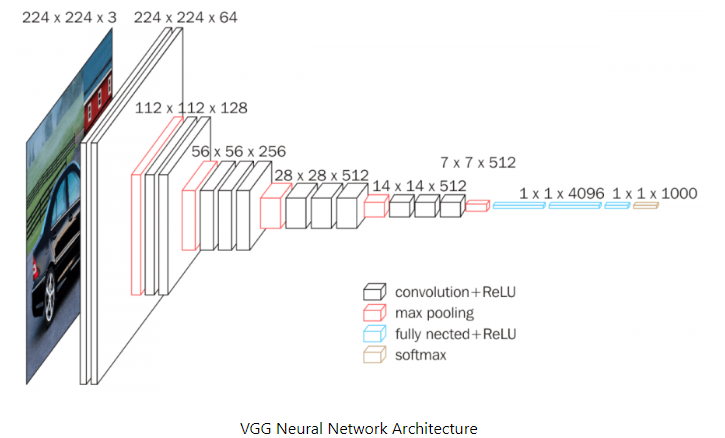
그럼에도 이해가 잘 안 되시는 분을 위해, VGG19 Net의 구조를 가져왔습니다. 빨간색 박스가 Max Pooling Layer입니다. Content Loss는 빨간색 박스를 통과하기 직전의 Feature Map을 활용하여 값을 산출합니다. 어디까지 통과시킬지는 여러 분의 선택이지만, 논문에서는 마지막 Pooling Layer 바로 직전까지 통과시킨 Feature Map을 활용하는 게 가장 성능이 좋다고 나옵니다. (SRGAN-VGG54 버전)
가짜 이미지와 진짜 이미지를 각각 Pooling Layer 직전까지 통과시켰을 때, 얻어지는 Feature Map들이 있을 텐데요. Content Loss는 이들 사이의 MSE 연산으로 정의할 수 있습니다.
SRGAN을 구성하는 생성자와 판별자의 구조에 대해 설명해 주세요.
SRGAN 아키텍처 소개: 생성자(Generator)
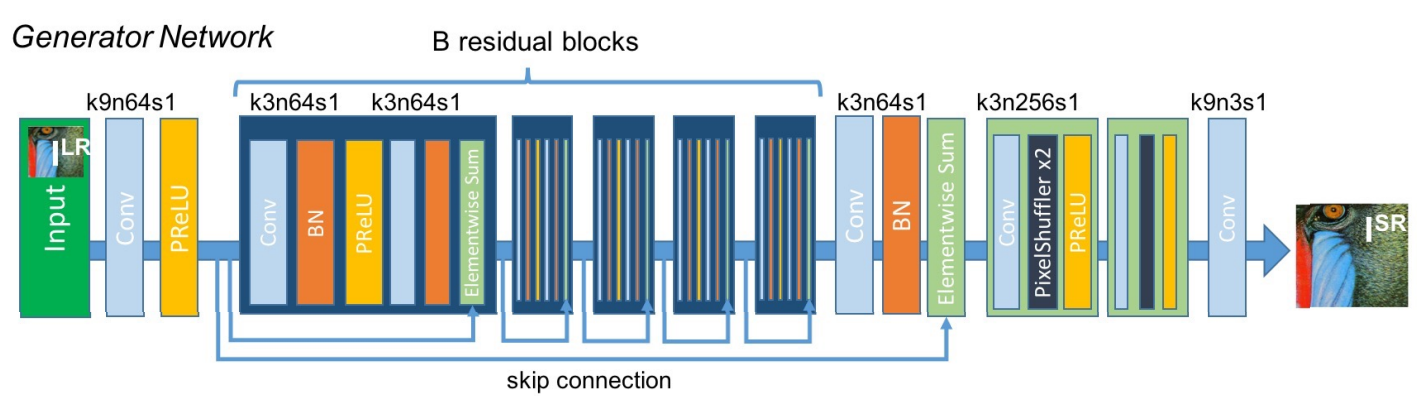
"4x 업스케일링"을 목적으로 한 생성자(Generator)의 아키텍처입니다. 중간 부분에 잔차 블록(Residual Blocks)을 여러 개 중첩했고, 뒷부분에는 PixelShuffler x2 역할을 하는 블록이 2개가 있습니다.
잔차 블록은 3x3 커널을 활용하고 64개의 특징맵을 추출하며 활성 함수로 PReLU를 사용합니다. 그리고 입력 이미지와 출력 이미지를 더해주는 Skip Connection이 존재합니다.
PixelShuffler x2는 이미지의 가로, 세로 비율을 2배로 늘려주는 역할을 합니다. 블록이 2개니까 총 4배를 업스케일링 하게 됩니다. 참고로 모델의 입력단이 아니라 마지막 Layer에 업스케일링을 진행하는 이유는 연산량 때문입니다. 입력단에서 업스케일링을 하지 않음으로써 학습 과정 전체적으로 작은 크기의 이미지를 사용해서 연산량이 감소합니다. 또한 필터 크기 역시 작게 활용할 수 있어서 연산량 측면에서 이점이 있습니다.
관련 내용과 PixelShuffler의 동작 방식에 대해서는 'ESPCN' 논문에 적혀 있는데, 본문 아래에 링크를 넣어 두었으니 관심 있으신 분들을 찾아보시면 좋을 것 같습니다.
SRGAN 아키텍처 소개: 판별자(Discriminator)
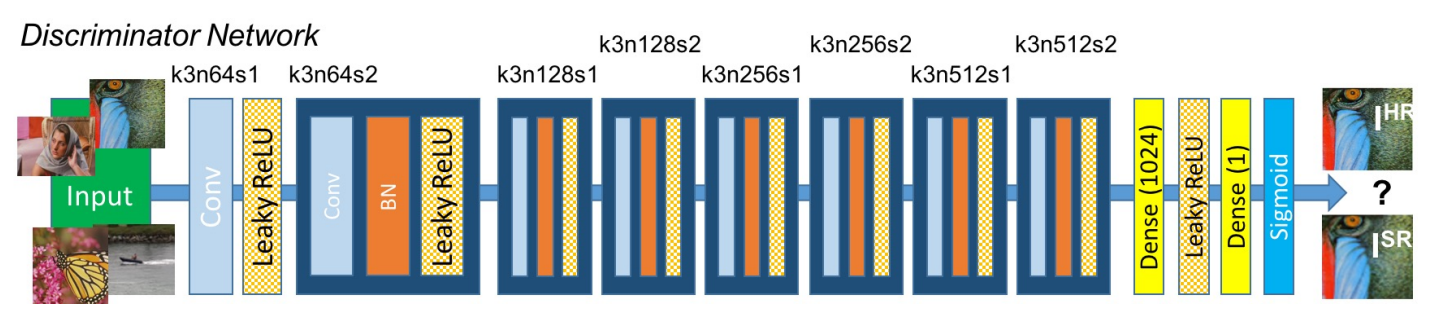
판별자는 기본적으로 3x3 필터를 사용합니다. 특징은 2배씩 늘어나는 Feature Map의 숫자인데요. 64개로 시작하여, Model의 마지막에는 512까지 증가합니다. 모델의 끝에는 생성자가 만든 SR 이미지인지, 진짜 HR 이미지인지 구분을 위해 Dense Layer와 Sigmoid 함수를 통과하도록 구성되어 있습니다. 따라서 자연스럽게 최종 결괏값은 확률이 됩니다.
참고로, 논문에는 Dense Layer를 활용했지만 Dense Layer는 모델의 파라미터 숫자를 급격하게 증가시키는 단점이 있습니다. 따라서 앞으로 구현할 코드에는 Dense Layer의 기능을 대체할 수 있는 Global Pooling을 활용할 예정입니다.
#3 Experiments
모델을 학습시키고 성능을 평가하다.
논문에서 모델을 학습시킨 방법
[1] 약 35만 장가량의 ImageNet 데이터 셋을 랜덤으로 샘플링하여 학습 데이터(Train Dataset)로 사용하고 Set5, Set14, BSD100과 같은 유명한 데이터셋을 통해 모델의 성능을 확인
[2] 저해상도 이미지는 ImageNet 데이터(HR)를 bicubic kernel을 사용하여 4배(downsampling factor r = 4)만큼 축소하여 획득. 참고로 고해상도 이미지는 크기가 크기 때문에 96 x 96 크기로 Crop 하여 사용.
[3] 저해상도 이미지는 [0,1] 사이의 값으로, 고해상도 이미지는 [-1,1] 사이의 값으로 Normalized
[4] Content Loss를 구하기 위해 Feature Map을 산출하여 VGG Loss를 구할 때, 기존의 MSE 수치와 너무 많은 값의 차이가 발생하지 않도록 1/12.25를 곱해서 값을 보정해 줌
[5] 최적화기는 Adam (beta1 = 0.9)를 활용
[6] Local Optima에 빠지지 않도록 먼저 SRResNet을 학습시키고, GAN 생성자(Generator)의 가중치를 학습한 SRResNet의 가중치로 초기화. SRResNet은 백만 번의 Iteration 동안 0.0001의 학습률로 학습됨.
[7] SRGAN을 학습할 때는 10만 번의 Iteration 동안 10^-4의 학습률로, 이후 10만 번의 Iteration 에는 학습률을 10^-5로 낮춰서 학습을 진행. 생성자와 판별자는 각각 번갈아 가면서 학습(k=1)
MOS(Mean Opinion Score)로 모델의 성능을 비교 평가
사람의 지각적 능력을 기준으로 모델 성능을 평가하기 위해 26명의 평가자가 SR 이미지에 1점부터 5점까지 점수를 부여합니다. 1점은 Bad Quality를 의미하고 5점은 Excellent Quality를 의미합니다.
NN(Neraset Neighbor), Bicubic, SRCNN과 같은 오래된 모델부터 SRGAN-VGG54까지 총 12개의 다른 모델에 대해 MOS 성능 평가를 진행합니다. 주요 버전에 대한 설명은 아래와 같습니다.
SRResNet: Residual Network를 SR 분야에 활용했다는 의미로, VGG Net을 의미합니다.
SRGAN-MSE: Content Loss로 MSE를 활용한 버전입니다.
SRGAN-VGG22: Content Loss를 구할 때, VGG의 2번째 Max-Pooling Layer 이전의 Feature Map을 활용한 버전입니다.
SRGAN-VGG54: Content Loss를 구할 때, VGG의 4번째 Max-Pooling Layer 이전의 Feature Map을 활용한 버전입니다
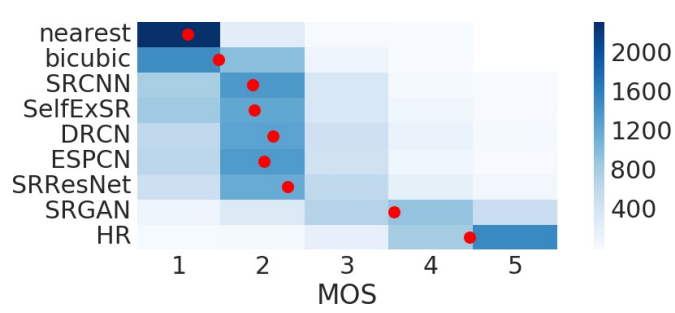
MOS 점수를 보면 역시 SRGAN의 평가가 가장 높은 것을 확인할 수 있습니다. 다만, 아직 원본 이미지의 수준에는 접근하지 못했네요.
생성자(Generator)의 성능 비교.

생성자의 성능을 직접 비교해 보겠습니다. 역시 SRGAN-VGG54 버전이 가장 미세한 질감을 잘 표현하네요. 다만 여기서도 아직은 원본 이미지급의 화질과는 차이가 보이네요.
#4,5 Discuission and future work & Conclusion
[1] Residual Network를 SR 분야에 적용하여 SRRenNet을 구현했으며, 모델을 깊게 쌓음으로써 성능 향상 효과를 확인함
[2] SRResNet으로도 MSE 기반의 측정 방식에서 SOTA를 달성함
[3] MSE 기반 학습의 단점을 지적하고 지각적 손실 함수를 도입하였으며 단순한 Computational efficiency가 아닌 사람이 느끼기에 좋은 고해상도, Perceptual Quality에 집중함 (참고로 이상적인 Loss Fucntion은 활용 분야마다 다르니, 자신의 분야에 맞는 적합한 Loss Function을 찾는 것이 핵심이라고 말합니다.)
[4] 4x 업스케일링 분야에서 SRGAN이 SOTA를 달성했으며 원본 이미지에 근접한 이미지를 생성할 수 있음을 제시
긴 글 읽어주셔서 감사합니다. 다음 시간에는 SRGAN의 논문 리뷰 내용을 바탕으로 직접 코드를 구현해 보도록 하겠습니다.
[참고] 학습에 참고한 문헌
#1 ESPCN: 모델의 마지막에 Upscaling을 진행하는 이유
[ESPCN 리뷰] Efficient Sub-Pixel Convolutional Neural Network (CVPR 16)
Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network My Summary & Opinion 기존의 다른 SISR network와는 다른 upscaling layer를 사용했다. 이전 네트워크들은 네트워크로 하여금
sofar-sogood.tistory.com
#2 ResNet: Residual Network & VGG 구조 소개
https://deep-learning-study.tistory.com/473
[논문 읽기] ResNet(2015) 리뷰
이번에 읽어볼 논문은 ResNet, 'Deep Residual Learning for Image Recognition' 입니다. ResNet은 residual repesentation 함수를 학습함으로써 신경망이 152 layer까지 가질 수 있습니다. ResNet은 이전 layer의 입력을 다음 l
deep-learning-study.tistory.com
'AI - Deep Learning > Super_Resolution' 카테고리의 다른 글
| [논문 구현] SRGAN(by Pytorch)을 활용한 Super Resolution Code (0) | 2023.06.27 |
|---|---|
| [논문 구현] SRCNN(by Pytorch)을 활용한 Super Resolution (6) | 2023.06.14 |
| [논문 구현] SRCNN(by Keras)을 활용한 Super Resolution (4) | 2023.06.13 |
| [논문리뷰] SRCNN: Image Super-Resolution Using Deep Convolutional Networks (1) | 2023.06.12 |




댓글