안녕하세요. 모두의 케빈입니다.
오늘은 불러온 데이터 프레임을 살펴보는 방법에 대해 배워보도록 하겠습니다.
■ 데이터 프레임의 정보 확인을 위한 여러 가지 방법들
Pandas로 불러온 데이터 프레임을 불러와보겠습니다. 데이터는 Kaggle의 학생들 성적 파일(exams)을 활용했습니다.
import pandas as pd
raw_data = pd.read_csv("exams.csv")
df = raw_data.iloc[:,[0,1,5,6,7]]
df.columns = ['성별','그룹','수학','국어','영어'] # 데이터 프레임의 컬럼명 재설정
df
데이터를 불러왔지만, 우리는 저 데이터가 도대체 어떻게 생겨먹었는지 알 수 없습니다. 직관적으로 전체 1,000개의 데이터가 있고 5개의 열로 구성되어 있구나, 정도로만 알 수 있을 뿐입니다. 데이터 분석을 하기 전에, 데이터의 특성을 파악하는 것은 중요한데요. 지금부터 불러온 데이터 프레임의 정보를 확인하는 방법에 대해 배워보도록 하겠습니다.
head(): 상위 데이터 불러오기
Pandas로 데이터를 불러온 뒤, 가장 먼저 확인해야 할 사항은 원하는 데이터를 올바르게 호출했는지의 여부입니다. 이 경우에는 굳이 모든 데이터를 호출할 필요가 없는데 이때 head() 방법을 사용합니다.
df.head() # default로 상위 5개 값을 호출
df.head(5) # 상위 5개 값을 호출
df.head(-5) # 밑에서 5개의 값을 제외하고 나머지 모든 값을 호출
tail(): 하위 데이터 불러오기
head()가 위에서부터 데이터를 불러왔다면, tail()은 아래서부터 데이터를 불러옵니다.
df.tail() # default로 하위 5개 값을 호출
df.tail(5) # 하위 5개 값을 호출
df.tail(-5) # 위에서 5개의 값을 제외하고 나머지 모든 값을 호출
Column(열) 이름만 불러오기 vs 순수한 값만 불러오기
columns 메서드를 활용하면 데이터 프레임의 열 이름만 리스트 형태로 반환하며, values 메서드를 사용하면 데이터 프레임의 값만 numpy.ndarray 형태로 반환합니다.
df.columns # Index(['성별', '그룹', '수학', '국어', '영어'], dtype='object')참고로 values는 데이터 프레임의 값을 numpy.ndarray로 반환하기 때문에, 행렬 연산인 dot product이 가능합니다. 따라서 pandas로 읽어온 데이터를 dot product 하기 위해서 values 메서드를 활용하기도 합니다.
df.values
shape: 데이터 프레임의 (m by n) 형태 확인
데이터 프레임의 행과 열의 숫자를 알고 싶다면 shape 메서드를 활용합니다.
df.shape # (1000,5)
info : 데이터 프레임 각 특성의 전반적인 정보 확인
데이터 프레임을 구성하고 있는 열 또는 특성들의 정보를 확인하기 위해서는 info() 함수를 사용합니다. 각각의 열 별로 이름, Null 값을 제외한 유효 값, 데이터의 타입을 확인할 수 있습니다.
df.info()
dtypes : 데이터 프레임 각 특성의 데이터 타입만 확인하기
각 열의 데이터 타입만 확인하고 싶을 때는 dtypes 메서드를 사용합니다.
df.dtypes
select_dtypes : 원하는 데이터 타입의 Column만 호출하기
원하는 데이터 타입의 Column만 호출하기 위해서는 select_dtypes() 함수를 사용합니다..
df.select_dtypes(include = 'object')
describe: 연속형 특성의 요약 통계량 확인
평균, 표준편차와 같은 통계량을 확인하기 위해서는 mean(), std(), median() 등의 함수를 사용합니다. 하지만 연속형 특성에 한해서, 한 번에 자주 사용하는 통계량을 보고 싶다면 describe() 함수를 사용하면 됩니다.
df.describe()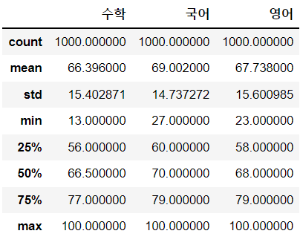
value_counts: 각각의 값이 나온 횟수를 확인하기
value_counts() 함수를 사용하면 각각의 개별 값이 얼마나 나왔는지 확인할 수 있습니다. 주로 Series에 적용합니다.
df["성별"].value_counts() # male 517, female 483물론, 각 열의 조합 값이 얼마나 나왔는지를 확인하고 싶은 특별한 경우에는 데이터 프레임에 직접 사용하기도 합니다. 아래의 결과 값을 보면 서로 다른 997개의 조합 값이 데이터 프레임 내에 있음을 알 수 있습니다. 이번 예제로는 적합하지 않은 데이터 셋이네요.
df.value_counts()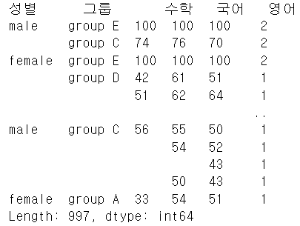
unique: 데이터 프레임의 컬럼 별 유일 값 확인하기
범주형(Category) 특성의 경우, 몇 가지 카테고리로 구분되어 있는지 확인하고 싶을 때 unique() 함수를 활용합니다. unique() 함수의 경우 데이터 프레임에 적용할 순 없으며, Series에만 적용 가능합니다. 결과 값은 numpy.ndarray 값으로 반환됩니다.
df["성별"].unique() # array(['male', 'female'], dtype=object)
읽어주셔서 감사합니다. 궁금하신 점이 있다면 댓글 남겨주세요. :)
'Python > Pandas' 카테고리의 다른 글
| 데이터 프레임 수정의 모든 것: 행, 열, Cell 값 추가/변경/제거 (0) | 2022.11.14 |
|---|---|
| [2편] 데이터 프레임 살펴보기: Null 값의 처리와 제어 (0) | 2022.11.13 |
| DataFrame 병합하기: concat, merge, join (0) | 2022.11.09 |
| Data Frame의 행, 열 선택하기: iloc과 loc의 차이점 (0) | 2022.11.07 |
| Python 기초: DataFrame 만들기 (0) | 2022.11.03 |



댓글