안녕하세요. 모두의 케빈입니다.
오늘은 실제 현업에서도 굉장히 많이 사용되는 Pandas 중, DataFrame를 만드는 방법에 대해 알아보겠습니다.
첫 번째 방법: read_excel(csv)
Excel 파일(또는 csv)를 Pandas로 불러오면, 자연스럽게 DataFrame 형태가 됩니다. 아마도 현업에서 가장 많이 사용하는 방법일 것 같습니다.
# DataFrame 생성
df = pd.read_excel("employee_list.xlsx")
df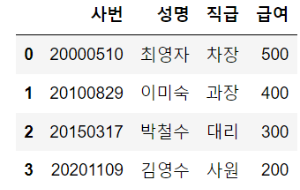
사번을 index로 사용하고 싶다면, 아래와 같이 지정해주세요.
df = pd.read_excel("employee_list.xlsx",index_col = "사번")
df
두 번째 방법: dictionary
종종 코딩을 하다보면, 직접 DataFrame을 선언해야 하는 경우가 있습니다. 이럴 때, 아래의 방법들을 활용해보세요. 우선 Python의 dictionary를 활용하는 방법입니다. dict를 활용하면 key값이 Column명이 됩니다.
employee_dict = {"사번":[20000510,20100829,20150317,20201109],
"성명":["최영자", "이미숙", "박철수", "김영수"],
"직급":["차장", "과장", "대리", "사원"],
"급여":[500,400,300,200]}
df = pd.DataFrame(employee_dict)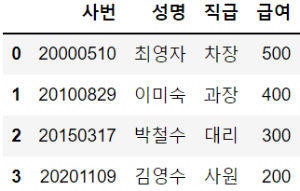
선언된 DataFrame의 index는 아래와 같이 변경합니다.
employee_dict = {"사번":[20000510,20100829,20150317,20201109],
"성명":["최영자", "이미숙", "박철수", "김영수"],
"직급":["차장", "과장", "대리", "사원"],
"급여":[500,400,300,200]}
df = pd.DataFrame(employee_dict)
df.set_index("사번", inplace=True)
df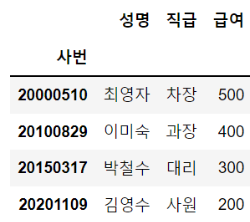
세 번째 방법: List 활용
친숙한 List를 활용해서 DataFrame을 만들 수 있다. 단, 이 경우 하나의 List가 DataFrame에서 하나의 행(Row)이 되는 점을 주의해야 합니다. (List를 차곡 차곡 아래에서부터 위로 쌓는다고 생각하세요.)
columns = ["사번","성명","직급","급여"]
row1 = [20000510, "최영자", "차장", 500]
row2 = [20100829, "이미숙", "과장", 400]
row3 = [20150317, "박철수", "대리", 300]
row4 = [20201109, "김영수", "사원", 200]
df = pd.DataFrame([row1,row2,row3,row4], columns = columns)
df.set_index("사번", inplace = True)
df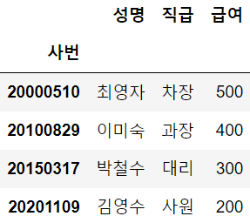
설정했던 Index는 변경할 수 있습니다. 단, 주의할 점은 index를 바로 변경하면 기존에 설정했던 index가 사라집니다. 사번을 index로 설정한 뒤, 변경하면 사번에 대한 정보가 사라지는 것입니다. 그래서, index를 변경할 때는 반드시 reset을 먼저 시켜줘야 합니다.
columns = ["사번","성명","직급","급여"]
row1 = [20000510, "최영자", "차장", 500]
row2 = [20100829, "이미숙", "과장", 400]
row3 = [20150317, "박철수", "대리", 300]
row4 = [20201109, "김영수", "사원", 200]
df = pd.DataFrame([row1,row2,row3,row4], columns = columns)
df.set_index("사번", inplace = True)
#index 초기화
df.reset_index(drop = False, inplace = True)
df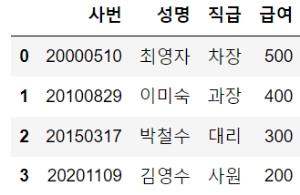
네 번째 방법: Numpy array
마지막으로 np.arrary를 활용하여 DataFrame을 만들어보겠습니다. 방법은 List와 동일합니다.
import numpy as np
columns = ["사번","성명","직급","급여"]
np_row1 = np.array([20000510, "최영자", "차장", 500])
np_row2 = np.array([20100829, "이미숙", "과장", 400])
np_row3 = np.array([20150317, "박철수", "대리", 300])
np_row4 = np.array([20201109, "김영수", "사원", 200])
df = pd.DataFrame([np_row1, np_row2, np_row3, np_row4], columns = columns)
df.set_index("사번", inplace = True)
df
'Python > Pandas' 카테고리의 다른 글
| 데이터 프레임 수정의 모든 것: 행, 열, Cell 값 추가/변경/제거 (0) | 2022.11.14 |
|---|---|
| [2편] 데이터 프레임 살펴보기: Null 값의 처리와 제어 (0) | 2022.11.13 |
| [1편] 데이터 프레임 살펴보기: head, tail, columns, values, shape, info, dtypes, describe, value_counts, unique (0) | 2022.11.10 |
| DataFrame 병합하기: concat, merge, join (0) | 2022.11.09 |
| Data Frame의 행, 열 선택하기: iloc과 loc의 차이점 (0) | 2022.11.07 |




댓글