안녕하세요. 모두의 케빈입니다.
오늘은 Data Frame을 병합하는 방법에 대해 알아보도록 하겠습니다.
■ Data Frame 병합
Pandas를 다루다 보면, 데이터 프레임을 합쳐야 하는 경우가 종종 생깁니다. Data Frame을 합치는 방법에는 크게 3가지가 있습니다. concat, merge, join이 그것인데요. 병합의 메커니즘이 조금씩 다르기 때문에 방법을 정확히 알고 상황에 맞게 사용하시면 됩니다. 자, 그러면 실습을 진행해볼까요?
Data 준비: kaggle "exams.csv"
실습에 사용하는 Data는 Kaggle에서 학생들의 시험 성적에 관한 파일을 사용했습니다. 실습을 위해 일부의 데이터만 사용하고, 조금 가공해보도록 하겠습니다.
import pandas as pd
raw_data = pd.read_csv("exams.csv")
raw_data.columns = ['성별','그룹','교육정도','점심','코스','수학','국어','영어']
# 원활한 실습을 위해 데이터의 일부만 사용
df1 = raw_data.iloc[0:5, [0,1,5,6,7]]
df2 = raw_data.iloc[5:10, [0,1,5,6]]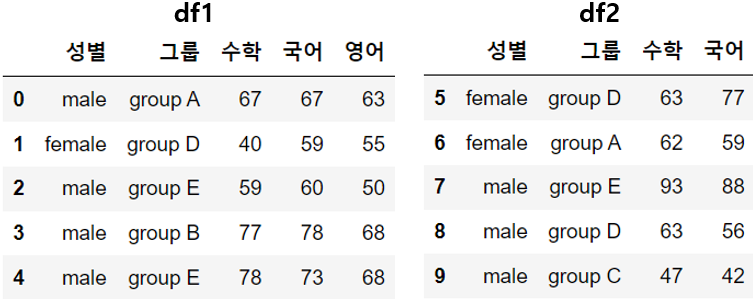
■ Concat
Concat : 데이터 프레임을 행, 열 기준으로 "단순" 병합하다.
Concat은 데이터 프레임을 순서대로 합치는 역할을 합니다. 가로 또는 세로 기준으로 연산이 가능합니다. default는 세로 방향 연산이며, 연산 시 없는 값이 있다면 자동으로 Null 값이 채워집니다.
df_concat = pd.concat([df1, df2])
df_concat
두 개의 데이터 프레임 df1과 df2를 세로 방향으로 붙였습니다. 이때, df2에는 "영어" 열이 없으므로, 해당 자리에는 Null 값이 채워지게 됩니다.
Concat 연산의 dafault 방향이 세로가 맞는지 확인하기 위해 기준 축을 직접 설정해보겠습니다. axis = 0은 세로를 의미하는데 아래 코드의 결과 값이 위와 동일한 것을 보면 concat의 default 연산은 세로(axis =0) 임을 알 수 있습니다.
df_concat = pd.concat([df1, df2], axis = 0)
df_concat
그렇다면 두 데이터 프레임에 공통으로 있는 열만 선택하여 합칠 수 없을까요? 그럴 땐 concat 내부의 join 옵션을 활용하면 됩니다. 두 데이터 프레임의 세로 연산(axis = 0)에서 기준은 열의 이름이므로 두 데이터 프레임에 모두 있는 성별, 그룹, 수학, 국어 열만 선택하여 병합합니다. (참고로 위에서 Null 값이 나온 이유는 concat의 join default가 outer이기 때문입니다.)
df_concat = pd.concat([df1, df2], axis = 0, join = 'inner')
df_concat
이번에는 가로(axis = 1)로 붙여보겠습니다. Null 값이 굉장히 많이 나오네요. 왜 그럴까요? 가로 연산의 기준은 "Index"이기 때문입니다. df1은 Index가 0부터 4까지이고 df2는 index가 5부터 9까지여서 두 데이터 프레임 사이에는 단 한 개의 Index도 중복되는 것이 없습니다. 그렇기 때문에 아래와 같이 Null 값이 많이 나오게 됩니다.
df_concat = pd.concat([df1, df2], axis = 1)
df_concat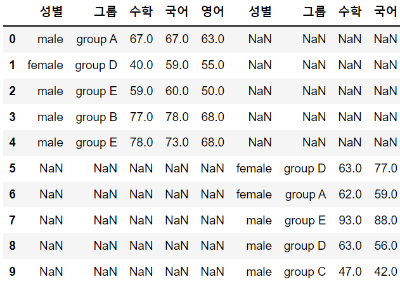
그렇다면 위의 두 데이터 프레임을 가로로 Null 값 없이 붙이기 위해서는 어떻게 해야 할까요? 아래처럼 df2의 index를 초기화시켜서 df1과 Index를 동일하게 맞춰주면 됩니다.
# 두 데이터 프레임의 index 초기화. df1은 사실 할 필요는 없다.
df1 = df1.reset_index(drop=True)
df2 = df2.reset_index(drop=True)
df_concat = pd.concat([df1,df2], axis = 1)
df_concat
■ Merge
merge : 기준 컬럼(열)을 설정하고, Key 값을 활용하여 데이터 프레임을 병합
Concat이 데이터 프레임을 단순 병합하는 기능이었다면, merge와 join은 Key값을 기준으로 데이터 프레임을 병합합니다. 이는 DB가 데이터를 호출하는 방식과 유사합니다.
merge는 엑셀의 VLOOKUP과 굉장히 유사한데요. 아래 예시를 통해 천천히 설명드리겠습니다. 보다 적합한 설명을 위해 새롭게 데이터 프레임을 만들어 보겠습니다.
import pandas as pd
df1 = pd.DataFrame({"사번":[1111,2222,3333,4444],
"성명":["김철수","최영수","박미자","이미선"],
"고과":["우수","미흡","보통","우수"]
})
df2 = pd.DataFrame({"사번": [1111,2222,3333,5555],
"급여": [200,300,400,500]})
df1 만 보면 그 사람의 급여를 알 수 없습니다. 반면 df2 만 보면 그 사번이 누구이고 고과가 무엇인지 알 수 없습니다. 이럴 경우, merge를 활용하여 두 데이터 프레임의 데이터를 합쳐줍니다.
df_merge = pd.merge(df1,df2)
df_merge
merge 연산의 기준이 되는 열을 지정해주지 않았기 때문에 두 데이터 프레임에서 이름이 같은 "사번" 열이 기준으로 자동 선정됩니다. 그리고 사번 값(Key)이 동일한 데이터를 두 데이터 프레임에서 뽑아와서 병합합니다.
결과를 보면 두 데이터 프레임에서 공통으로 있는 사번의 데이터만 병합했다는 점인데요. 이처럼 교집합의 데이터만 병합하는 방식을 "inner"라고 합니다. (참고로 병합 방식에는 left, right, inner, outer가 있습니다.)
merge의 옵션 중에 how와 on이 있습니다. how는 데이터 병합 방식을 설정하고, on은 연산의 기준이 되는 열을 지정해줍니다.
df_merge = pd.merge(df1,df2, how = "inner", on = "사번")
df_merge #위와 동일한 결과가 나온다.
반면, 두 데이터 프레임의 기준 열이 이름만 다른 경우가 있습니다. 아래처럼 같은 의미이지만 df1에서는 사번으로, df2에서는 ID로 되어 있다면 merge 할 때 새롭게 옵션을 부여해야 합니다.
import pandas as pd
df1 = pd.DataFrame({"사번":[1111,2222,3333,4444],
"성명":["김철수","최영수","박미자","이미선"],
"고과":["우수","미흡","보통","우수"]
})
df2 = pd.DataFrame({"ID": [1111,2222,3333,5555],
"급여": [200,300,400,500]})
left_on은 왼쪽 데이터 프레임(df1)의 기준 열을, right_on은 오른쪽 데이터 프레임(df2)의 기준 열을 설정해줍니다.
how = left를 설정하면 df1의 데이터는 모두 사용하고 없는 부분은 Null 값으로 채워집니다. right와 outer는 아래 join 예시에서 설명하도록 하겠습니다.
df_merge = pd.merge(df1,df2, left_on = "사번", right_on ="ID", how = 'left')
df_merge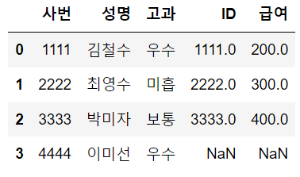
■ Join
Join: 기준 행을 설정하고, Key 값을 활용하여 데이터 프레임을 병합
merge가 열 기준이라면 join은 행(index)을 기준으로 두 데이터 프레임을 병합합니다.
df_join = df1.join(df2)
df_join
두 데이터 프레임 모두 Index가 0부터 3까지로 동일하기 때문에 위처럼 단순 병합되었습니다. 이것은 저희가 원하는 결과가 아니겠죠? 사번을 기준으로 join 하기 위해서는 두 데이터 프레임의 Index로 사번을 설정해주어야 합니다.
df1 = df1.set_index("사번")
df2 = df2.set_index("ID")
df_join = df1.join(df2)
df_join
아주 재밌네요. merge에서는 inner가 default였다면 join은 left가 default인가 봅니다. merge에서 inner와 left 실습을 했으므로, join에서는 right와 outer 실습을 해보겠습니다. (inner는 직접 해보시기 바랍니다.)
df_join = df1.join(df2, how = 'right')
df_join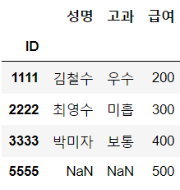
df_join = df1.join(df2, how = 'outer')
df_join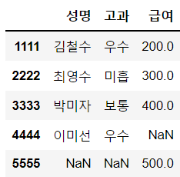
긴 글 읽어주셔서 감사합니다. 궁금하신 점은 댓글로 남겨주세요. :)
'Python > Pandas' 카테고리의 다른 글
| 데이터 프레임 수정의 모든 것: 행, 열, Cell 값 추가/변경/제거 (0) | 2022.11.14 |
|---|---|
| [2편] 데이터 프레임 살펴보기: Null 값의 처리와 제어 (0) | 2022.11.13 |
| [1편] 데이터 프레임 살펴보기: head, tail, columns, values, shape, info, dtypes, describe, value_counts, unique (0) | 2022.11.10 |
| Data Frame의 행, 열 선택하기: iloc과 loc의 차이점 (0) | 2022.11.07 |
| Python 기초: DataFrame 만들기 (0) | 2022.11.03 |




댓글